Put asset health in context to effectively adopt predictive maintenance
Most operations already track asset health in some way - fault history, vibration, temperatures, alarms, inspections – but health data in isolation can be misleading, and is often not useful to front line teams and those without significant engineering support.
Asset health becomes meaningful to operations when you can see it against:
Actual load and duty cycles over time (how hard the asset has been worked)
Work history across reactive, planned and condition‑based tasks (how much effort was put in to maintain health)
System performance, constraints and bottlenecks (how well did the asset perform under real operating loads)
You cannot learn true asset health without understanding the combined effect of load, maintenance history and the system the asset sits within. This is where a site‑level digital twin becomes powerful: it keeps the process view and the asset view together, so you can see how asset performance drives throughput, quality, safety and cost, rather than treating each piece of equipment as an island.
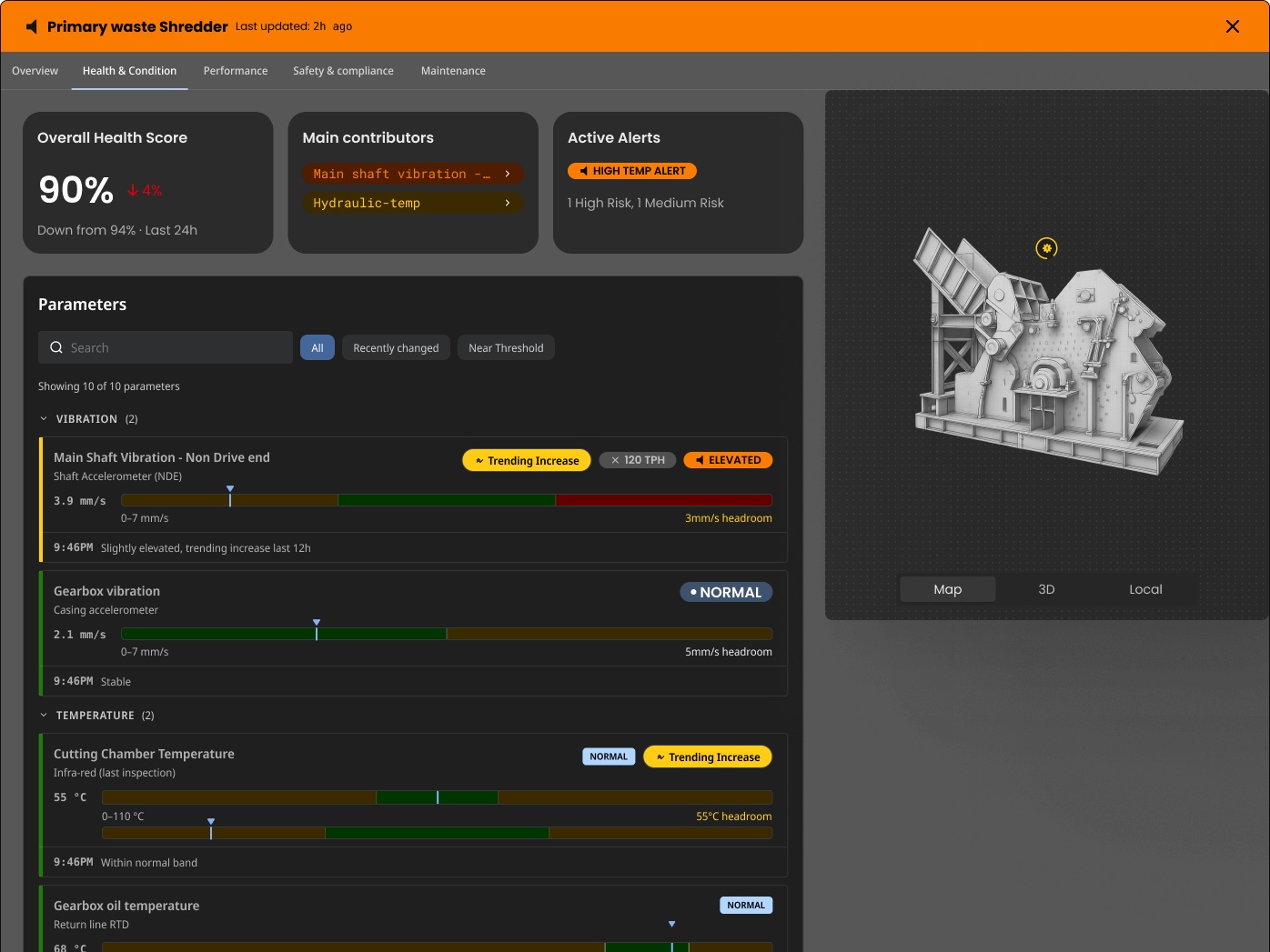
Real time Asset Health is a critical enabler of Predictive Maintenance, and usually requires fusion of data from multiple sources (SCADA/PLC + EAM/CMMS)
A disaggregated view of predictive models
Under the label “predictive maintenance” sit several very different model types. Each has strengths and trade‑offs, and the real value comes from combining them thoughtfully, not attempting to pick a single winner.
General / statistical models: These models look for correlations and trends across large volumes of asset and process data. They are fast to deploy and useful for identifying broad risk patterns, but they can be hard to interpret and may not capture specific failure modes.
OEM “black box” models: Many OEMs now ship equipment with embedded diagnostics and predictive outputs. These models often perform well for the scenarios they were trained on, but are opaque to the operator and difficult to adapt when operating conditions drift away from (or never matched) design assumptions.
Models trained on asset classes: Class‑based models aggregate behaviour from a group of similar assets (for example, all slurry pumps of a given size and service). They are relatively efficient to train and maintain, if sufficient data is available, and they help standardise tactics across a fleet. However, they can miss the nuances of individual “asset personality” – the subtle but critical differences that arise from installation, up and downstream piping, consumables/rotable parts variations and operating regimes.
Models trained on individual assets: For your most critical assets, there is often a strong case for building individual models that learn from that asset’s specific operating history, failures and interventions. These models are more expensive to create and maintain, but can capture complex local effects that fleet‑level models smooth out. They are, however, often not reusable on other assets, even the same brand/model.
The distinction between class‑level and individual models is critical. If you treat everything as a class problem, you risk missing the subtle signals that precede a catastrophic failure in a unique, high‑criticality asset. If you over‑invest in individual models, you create an unmanageable governance burden and struggle to scale normalised learnings across the portfolio.
The goal is a valuable portfolio: general models for the site, class models for most of the fleet, individual models for critical assets that genuinely warrant it.
The Geminum Site Twin is designed to hold this disaggregated view: the same asset may be covered by an OEM black box, a class model and an individual model, and the twin becomes the place where predictions, confidence and context are reconciled so the organisation can choose which “model” to trust for a given decision.
The real blockers: governance, time and change
Most organisations do not fail at predictive maintenance because of algorithms; they stall on governance and operating rhythms that undermine the learning loops necessary to tune algorithms.
Predictive models are successful when many predictions and actions can be learned from to improve future predictions and actions. Adoption and learning drives improvements. Lack of adoption and decoupled predictions from outcomes prevent learning.
Key blockers we see repeatedly:
Governance of “the model”: Depending on the data available and the history you have, “the model” might be a human expert, a simple rule set, an OEM black box or an AI model – and the type of model and the accuracy of the model can and should change over time. If roles and decision rights are fuzzy, people default to what they know/trust, even if it is less accurate.
Time horizon and thresholds: Predictive signals are only useful if they align with your planning horizons and risk appetite. Predicting a failure five minutes ahead is interesting but not actionable if your maintenance approval window is weeks. Conversely, extremely conservative thresholds can flood planners with noise.
Multiple models providing contradictory signals: Multiple models providing contradictory signals can be enough to drive planners back to the BAU plan, especially if they are being asked to choose the “right” prediction and vary schedules.
Inability to change the schedule: Everyone already has scheduled and reactive maintenance. If you cannot flex the schedule to act on predictions – to add inspections, bring work forward or create new tasks – then the models will create little value. The best predictions in the world are wasted if the weekly and shutdown cycles cannot absorb change.
Over‑correction and unintended consequences: If you change too often or too aggressively based on early predictive signals, you may alter asset behaviour in unexpected ways, introduce new failure modes or move problems upstream or downstream in the process. Change is constant, and causality is hard to establish inside a complex system.
The Geminum Site Twin is built to support this governance layer. It connects asset health, work history, process performance and risk into a single, shared picture, so that planners, maintainers and operations can see the impact of each decision. In practice, the twin becomes the environment where human, OEM, statistical and ML model outputs are all visible, their assumptions are explicit, and you can choose which guidance to follow for a given context in order to change or create work or change operating plans.
Iteration is the strategy, not a phase
Iteration is the strategy, not a phase
There is no final steady state in predictive maintenance. New equipment, major upgrades, feed variation, control changes and rotable parts all shift system behaviour in ways that are difficult to predict in advance.
Some practical patterns:
Major upgrades can create step changes in how assets behave, both locally and across the system. What used to be a bottleneck may disappear, and a new constraint will emerge elsewhere
Rotable parts can create step change behaviour in one asset and almost no visible effect in another, until a sudden failure reveals a hidden interaction
Each significant change is a new experiment. Models need to be retrained, thresholds revisited and assumptions tested.
A useful way to think about this is that your asset and process models are never “done”. You are continually searching for new optimal points: when to inspect, when to intervene, when to replace, and when to accept risk. The learning is not just about the asset; it is also about where else you need data, and where current data is inadequate or misleading.
The Geminum Site Twin treats model evolution as an explicit event. New signals, new equipment, new rules and new models can be added without losing historical context. You can see, on a timeline, how changes in equipment, work tactics or operating modes affected performance, and use that feedback to refine both your models and your governance. The event state of assets is constantly changing, and tracking and timelining related events is critical to root cause analysis and trading off work vs production.
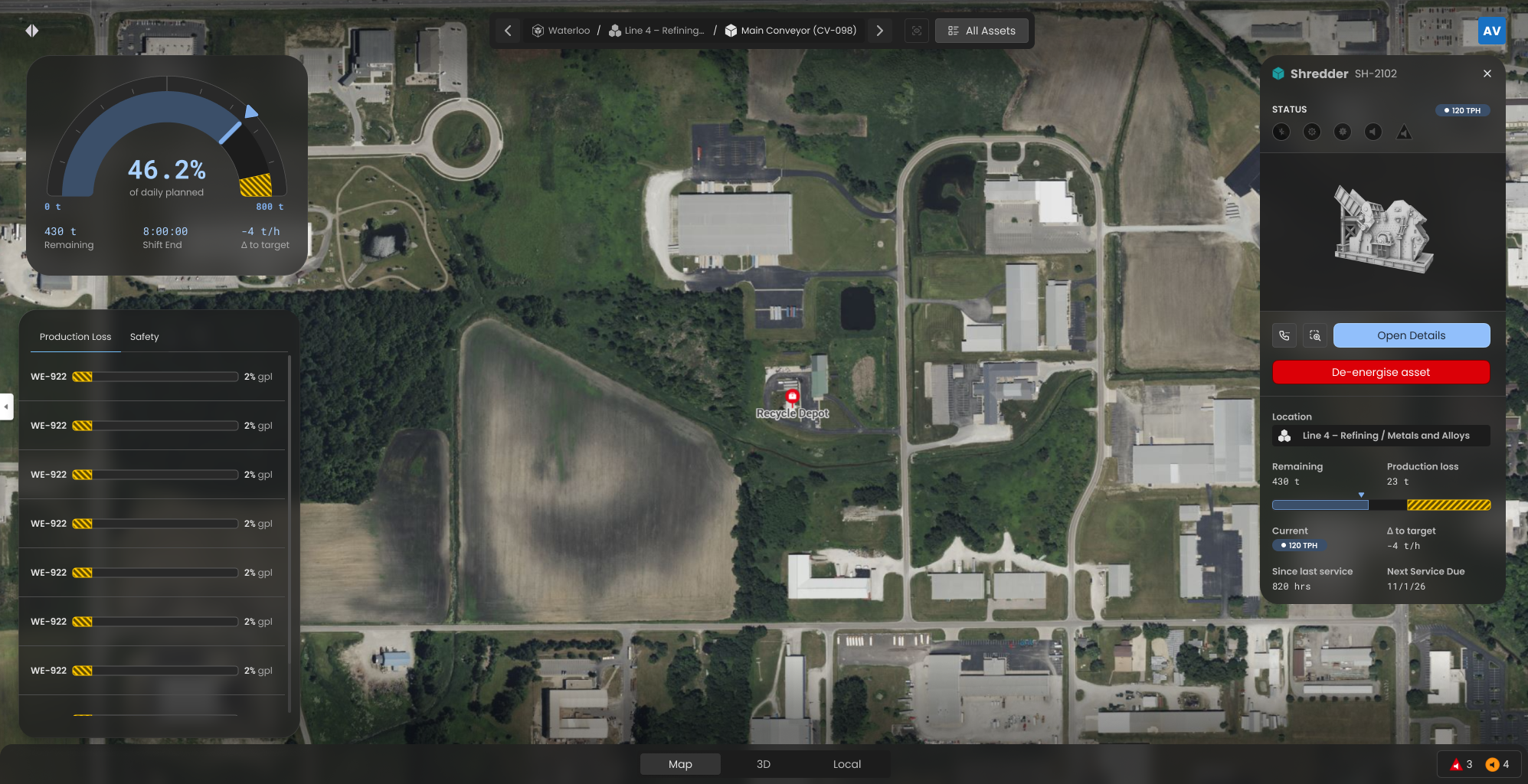
Asset Health + Geospatial opens the door to effective work management.
The four stages of predictive maintenance maturity
Many maturity models are too abstract to guide day‑to‑day decisions. We use a practical staging approach that can be applied asset by asset and system by system.
Stage 1: System Visibility
Objective: See what is happening across the system and to the asset.
You consolidate:
Asset data (past and present), including sensor readings, events and states
Work history (past, present, scheduled and approved)
System performance and load, including throughput, utilisation and constraints.
At this stage you are not yet predicting; you are building a trustworthy, connected view. For many sites, this alone is a significant step up from spreadsheets, siloed systems and tribal knowledge.
How the Geminum Site Twin supports Stage 1:
Connect asset registers, CMMS/EAM data, SCADA/PLC/historian data into a single contextual model
Create an asset graph showing relationships between assets, process/water/power/reagent flows
Create a production constraint model that identifies and quantifies production losses in real time, and identifies local (buffer constrained) vs global constraints
Provides a site‑wide process and equipment view, so leaders can drill down from a system issue (e.g. throughput loss or fault) down to specific assets and their work and health timelines.
It is normal, and healthy, to have only some of the site at Stage 1 while you focus on getting the basics right.
Stage 2: Contextual Prediction Visibility
Objective: Anticipate likely failures or degradations.
At this stage you:
Deploy initial predictive models (OEM, statistical, class‑based) on selected assets
Start to see predicted anomalies, remaining useful life estimates or risk scores
Begin to differentiate between asset classes where models work well and those where signals are noisy.
How the Geminum Site Twin supports Stage 2:
Connects or hosts multiple model types side‑by‑side, attached to the same asset and process context (one asset to many models and one model to many assets)
Visualises predictions against production and work plans, so teams see not just that “Asset A is at risk”, but what that may mean for production and work plans, including related/up/downstream assets.
Stage 2 is where the difference between class and individual models becomes very apparent. The Site Twin helps you decide where to stay general and where to invest in asset‑specific learning.
Stage 3: Rapid governance
Objective: Respond quickly and consistently to actual and predictive information.
You move from “look at all the faults and predictions” to “let’s change this now” by:
Defining who is allowed to change plans, under what conditions, and how that is recorded.
Setting practical thresholds for different model types and different assets.
Embedding predictive signals into existing planning and control rhythms (daily, weekly, shutdown).
How the Geminum Site Twin supports Stage 3:
Provides a shared “single place” where operations, maintenance and planning see the same asset condition, asset predictions and system performance, and can collaborate in real time (e.g. via Microsoft Teams integration or inside the Site Twin) to make decisions and take actions
Captures decisions, overrides and outcomes, via the event graph, so you build a strong supporting feedback loop on both the governance and the models
Create rapid work changes by creating new work orders in your EAM/CMMS for approval or modifying existing work order timing, in response to both faults and predictions
Makes it easy to compare similar assets with different tactics, revealing where class‑level models need refinement or where individual behaviour dominates
Compare historic predictions to current predictions to historic faults for a given asset, to understand how predictions themselves are changing over time. Very often the rate of change and quantum of change of predictions is a valuable input to decisions.
This is still a reactive stage - changes are triggered by events or predictions - but the organisation is now comfortable adjusting work and operating behaviour in response to potential and likely changes in the real world.
At this stage, you will likely see most assets in Stage 1, multiple assets in Stage 2 (especially those with OEM models) with a subset entering Stage 3 as you prove governance patterns on assets with the most understood models. Often, the “most critical” assets are not the ones you experiment with, but they are the ones that can benefit the most by being in Stage 2 for longer periods.
Stage 4: Targeted prescription (planned, scheduled, reactive)
Objective: Integrate predictive and prescriptive maintenance into the full planning horizon.
By Stage 4, for selected high‑value assets and systems you can:
Co‑design plan changes, schedules and contingencies with the Site Twin, using well‑understood models and impact assessments
Blend planned, scheduled and reactive work around predictive insights, rather than bolting predictions onto existing calendars
Quantify benefits (reduced downtime, improved throughput, lower risk) and reinvest them into further model development and data collection.
How the Geminum Site Twin supports Stage 4:
Acts as the “home” for stable, well‑governed prescriptive playbooks: for a given asset and scenario, everyone can see the recommended actions, expected health and production impact and governance path.
Scales learning: what you learn on a few high‑value assets can be gradually propagated to similar classes, or adapted for new equipment.
At any point in time, it is normal for:
Most equipment to sit at Stage 1 (visibility only)
A subset - often constrained or critical systems - to operate around Stages 2–3
A small number of well understood assets to operate at Stage 4.
Crucially, new equipment and assets start at Stage 1 and progressively move through the stages as data, models and governance mature. Changes to operating routines or parts may drive some assets from Stage 4 back to 2, until you understand the new behaviours and health metrics and impacts.
This is not a once‑off journey; it is ongoing, which is why the Site Twin is a persistent orchestration tool, not a framework or new silo.
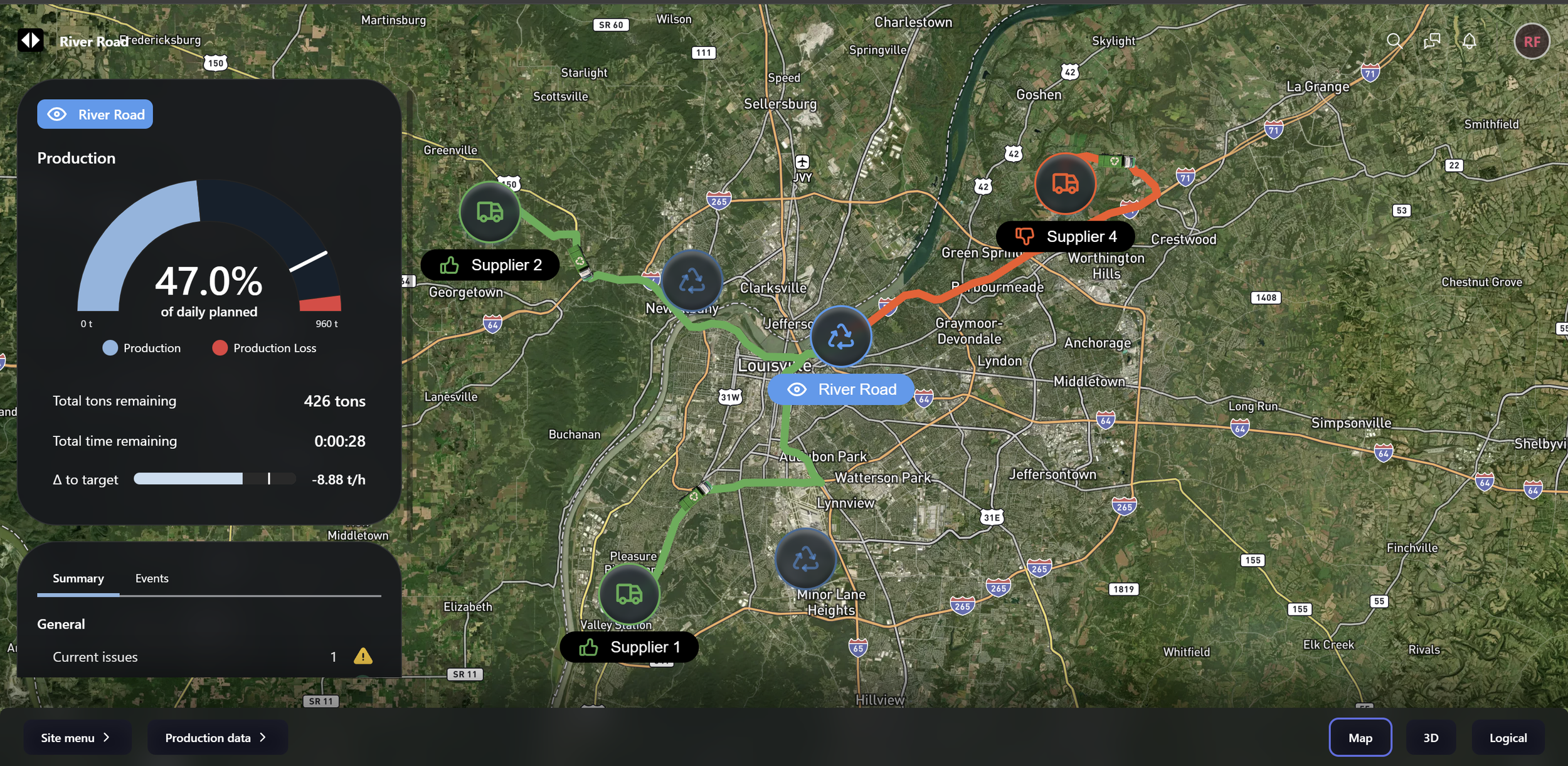
Value Chain view - look across your value chains, from supply to processing, to identify current bottlenecks and forecast future bottlenecks
How the Geminum Site Twin ties it together
Bringing this back to practical implementation, the Site Twin provides four core capabilities that make these stages achievable:
A unified systems model of the site: process, assets & maintenance in context, so you can always see asset health and predictions in terms of their impact on the system
A home for multiple model types: human rules, OEM black boxes, statistical and AI models, both class‑level and individual, where model outputs can be compared, governed and improved
A learning environment: capturing not just data and predictions, but the work you perform, the outcomes you see and the changes you make, so each iteration raises your confidence and expands the set of assets that can move to higher stages
Clear paths for action: users can suggest new work orders, alter existing work, approve system generated work orders (on faults and predictions) and collaborate in real time with other people and teams to decide and act quickly
For many organisations, the first step should not be “which model is the best”; it is to connect existing data and practices into a coherent, navigable and analysable picture. From there, you can gradually introduce prediction, prediction governance and prescription where the value and readiness are highest. There’s no need to rip and replace existing systems - you will need your ERP & EAM to still do their jobs, but now you have a Site Twin that sits over the top to orchestrate and govern cross-functional and intra-plan changes.